
RxExample GitHubSearchRepositories
如何友好地做请求一个分页列表,需要注意下一页的链接在当前页返回的结果,又如何连续请求直到请求到最后一页?
返回 json 格式大概如下所示:
{
"data": { },
"next": "url"
}
阅读本文你可能需要先阅读这几篇文章 RxExample GitHubSignup 部分代码解读、RxSwift - 为什么存在 catchError、RxSwift 定制重试逻辑 。
GitHubSearchRepositories 是一个相对完整的列表加载示例项目。在该项目中,你可以了解到如何合理地做错误重试,如何合理地管理异步状态,以及如何处理列表分页加载问题。
该项目完成了一个搜索 GitHub 仓库的的代码,支持多页加载,你可以先运行项目了解一下项目的基本功能。
本节代码相对有些复杂,我们先从 GitHubSearchRepositoriesAPI 的使用入手,即我们先来关注 GitHubSearchRepositoriesViewController 的代码。
# 触发搜索事件
如下代码完成了对搜索事件的处理:
let searchResult = self.searchBar.rx.text.orEmpty.asDriver()
.throttle(0.3)
.distinctUntilChanged()
.flatMapLatest { query -> Driver<RepositoriesState> in
if query.isEmpty {
return Driver.just(RepositoriesState.empty)
} else {
return GitHubSearchRepositoriesAPI.sharedAPI.search(query, loadNextPageTrigger: loadNextPageTrigger)
.asDriver(onErrorJustReturn: RepositoriesState.empty)
}
}
我们通过 throttle 和 distinctUntilChanged 操作符对搜索事件进行一定优化,分别是 0.3 秒的延时和去重操作。毕竟在频繁输入文字时,调用搜索接口对服务器是一个较大的负担。
当查询结果为空时,我们可以直接返回 RepositoriesState.empty 表示搜索结果为空。
当结果不为空时,调用 GitHubSearchRepositoriesAPI 提供的搜索方法,当接口调用出错时,直接返回 RepositoriesState.empty 。这里使用的是 Driver ,我们无需担心重复订阅和错误处理。
# 加载下一页
需要注意的是,搜索的方法需要一个 loadNextPageTrigger 参数,这个参数用来处理加载下一页问题,它的类型是 Observable<Void> 。
我们的 loadNextPageTrigger 是对 tableView 滑动位置进行监听,达到预期位置加载下一页:
let loadNextPageTrigger = self.tableView.rx.contentOffset
.flatMap { _ in
return tableView.isNearBottomEdge(edgeOffset: 20.0)
? Observable.just(())
: Observable.empty()
}
isNearBottomEdge 是一个扩展方法:
extension UIScrollView {
func isNearBottomEdge(edgeOffset: CGFloat = 20.0) -> Bool {
return self.contentOffset.y + self.frame.size.height + edgeOffset > self.contentSize.height
}
}
默认滑出 20 个点触发加载下一页的事件。
对于网络请求状态,我们用状态栏的菊花表示:
GitHubSearchRepositoriesAPI.sharedAPI.activityIndicator
.drive(UIApplication.shared.rx.isNetworkActivityIndicatorVisible)
.disposed(by: disposeBag)
此外还有对于请求服务状态的处理:
searchResult
.map { $0.serviceState }
.drive(navigationController!.rx.serviceState)
.disposed(by: disposeBag)
searchResult
.filter { $0.limitExceeded }
.drive(onNext: { n in
showAlert("Exceeded limit of 10 non authenticated requests per minute for GitHub API. Please wait a minute. :(\nhttps://developer.github.com/v3/#rate-limiting")
})
.disposed(by: disposeBag)
我们添加了网络状态的展示和 GitHub 请求受到限制的提示。
再加上数据的填充,这基本就完成了这个搜索的例子。
# GitHubSearchRepositoriesAPI
现在让我们关注 GitHubSearchRepositoriesAPI 的设计。
RepositoriesState 表示了对仓库请求的状态,包括请求到的仓库列表,网络状态和是否受到 GitHub 请求限制。
本节有趣的是下一页请求的链接我们是默认不知道的,是通过服务器返回给我们而确定链接是什么,当然我们也可能遇到下一页请求的链接是确定的场景。这取决于你和后端程序员的约定。
因为 GitHub 对未申请 Developer 认证的请求会有一定限制,每分钟我们只能请求十次 API 。
代码如下:
/**
This is the final result of loading. Crème de la crème.
*/
struct RepositoriesState {
/**
List of parsed repositories ready to be shown in the UI.
*/
let repositories: [Repository]
/**
Current network state.
*/
let serviceState: ServiceState?
/**
Limit exceeded
*/
let limitExceeded: Bool
static let empty = RepositoriesState(repositories: [], serviceState: nil, limitExceeded: false)
}
我们还提供了一个静态变量,方便提供一个空状态的展示。我们直接使用 RepositoriesState 和业务逻辑进行交互。
ServiceState 提供了离线和在线的描述:
enum ServiceState {
case online
case offline
}
当你的手机未连接到任何网络时,为离线 offline 状态。
对于 GitHub 仓库信息的描述,我们提供了名字和链接:
struct Repository: CustomDebugStringConvertible {
var name: String
var url: String
init(name: String, url: String) {
self.name = name
self.url = url
}
}
extension Repository {
var debugDescription: String {
return "\(name) | \(url)"
}
}
还有一个结构体用来处理网络加载数据结果:
enum SearchRepositoryResponse {
/**
New repositories just fetched
*/
case repositories(repositories: [Repository], nextURL: URL?)
/**
In case there was some problem fetching data from service, this will be returned.
It really doesn't matter if that is a failure in network layer, parsing error or something else.
In case data can't be read and parsed properly, something is wrong with server response.
*/
case serviceOffline
/**
This example uses unauthenticated GitHub API. That API does have throttling policy and you won't
be able to make more then 10 requests per minute.
That is actually an awesome scenario to demonstrate complex retries using alert views and combination of timers.
Just search like mad, and everything will be handled right.
*/
case limitExceeded
}
是时候关注最核心的部分了。
从 search 方法入手:
extension GitHubSearchRepositoriesAPI {
/**
Public fascade for search.
*/
func search(_ query: String, loadNextPageTrigger: Observable<Void>) -> Observable<RepositoriesState> {
let escapedQuery = query.URLEscaped
let url = URL(string: "https://api.github.com/search/repositories?q=\(escapedQuery)")!
return recursivelySearch([], loadNextURL: url, loadNextPageTrigger: loadNextPageTrigger)
// Here we go again
.startWith(RepositoriesState.empty)
}
}
search 调用了 recursivelySearch 方法,并将 loadNextPageTrigger 传递进去。同时我们还返回了一个空状态表示初始状态。
这个名字为递归搜索的 recursivelySearch 是本节一个核心逻辑。
你可以结合这张图了解 recursivelySearch 的完整流程:
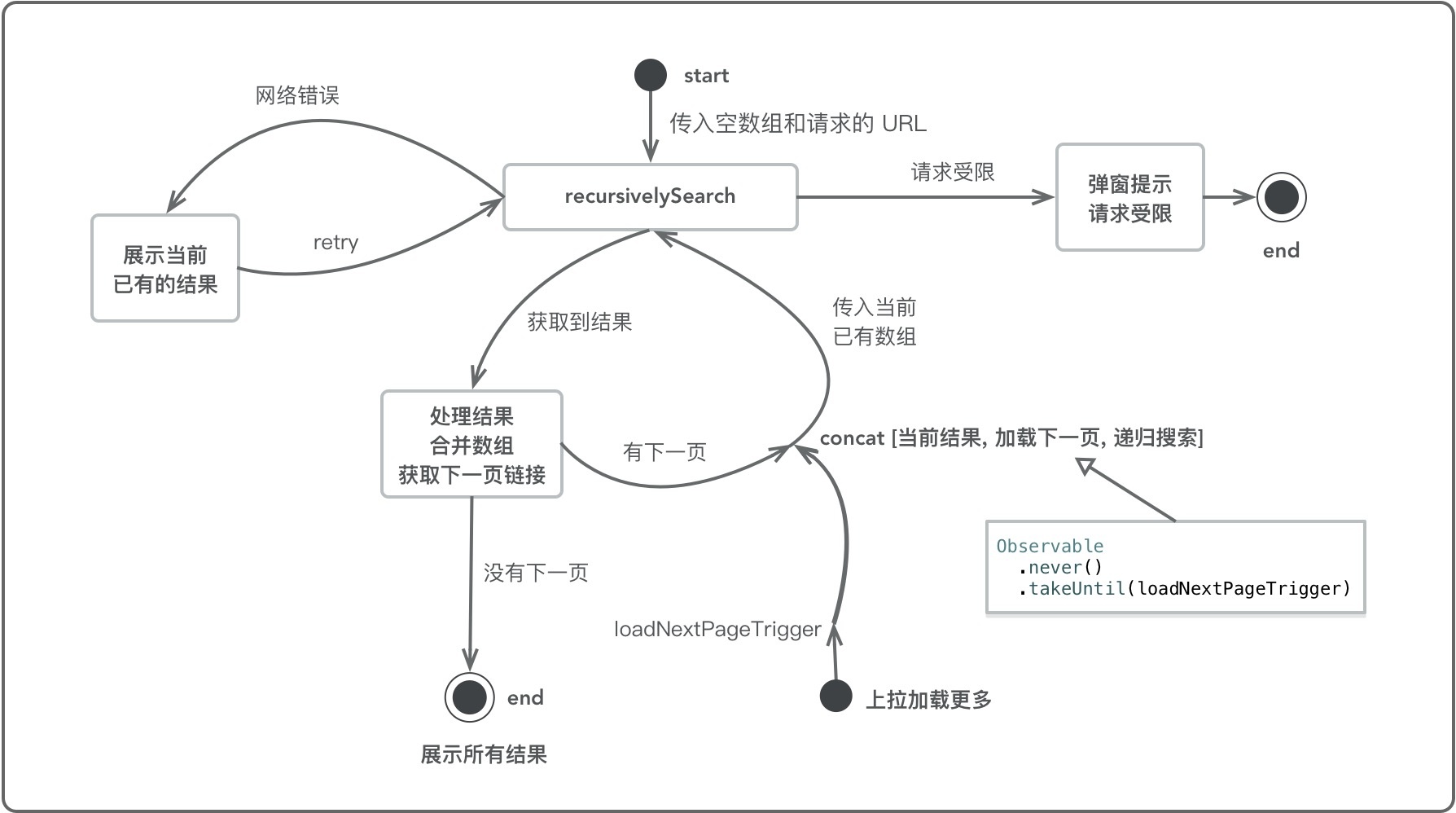
private func recursivelySearch(_ loadedSoFar: [Repository], loadNextURL: URL, loadNextPageTrigger: Observable<Void>) -> Observable<RepositoriesState> {
return loadSearchURL(loadNextURL).flatMap { searchResponse -> Observable<RepositoriesState> in
switch searchResponse {
/**
If service is offline, that's ok, that means that this isn't the last thing we've heard from that API.
It will retry until either battery drains, you become angry and close the app or evil machine comes back
from the future, steals your device and Googles Sarah Connor's address.
*/
case .serviceOffline:
return Observable.just(RepositoriesState(repositories: loadedSoFar, serviceState: .offline, limitExceeded: false))
case .limitExceeded:
return Observable.just(RepositoriesState(repositories: loadedSoFar, serviceState: .online, limitExceeded: true))
case let .repositories(newPageRepositories, maybeNextURL):
var loadedRepositories = loadedSoFar
loadedRepositories.append(contentsOf: newPageRepositories)
let appenedRepositories = RepositoriesState(repositories: loadedRepositories, serviceState: .online, limitExceeded: false)
// if next page can't be loaded, just return what was loaded, and stop
guard let nextURL = maybeNextURL else {
return Observable.just(appenedRepositories)
}
return Observable.concat([
// return loaded immediately
Observable.just(appenedRepositories),
// wait until next page can be loaded
Observable.never().takeUntil(loadNextPageTrigger),
// load next page
self.recursivelySearch(loadedRepositories, loadNextURL: nextURL, loadNextPageTrigger: loadNextPageTrigger)
])
}
}
}
首先它调用了 loadSearchURL 获取下一页,返回一个 Observable<SearchRepositoryResponse> 。
来看 loadSearchURL 方法:
private func loadSearchURL(_ searchURL: URL) -> Observable<SearchRepositoryResponse> {
return URLSession.shared
.rx.response(request: URLRequest(url: searchURL))
.retry(3)
.trackActivity(self.activityIndicator)
.observeOn(Dependencies.sharedDependencies.backgroundWorkScheduler)
.map { httpResponse, data -> SearchRepositoryResponse in
if httpResponse.statusCode == 403 {
return .limitExceeded
}
let jsonRoot = try GitHubSearchRepositoriesAPI.parseJSON(httpResponse, data: data)
guard let json = jsonRoot as? [String: AnyObject] else {
throw exampleError("Casting to dictionary failed")
}
let repositories = try GitHubSearchRepositoriesAPI.parseRepositories(json)
let nextURL = try GitHubSearchRepositoriesAPI.parseNextURL(httpResponse)
return .repositories(repositories: repositories, nextURL: nextURL)
}
.retryOnBecomesReachable(.serviceOffline, reachabilityService: _reachabilityService)
}
在这里我们通过使用 trackActivity 处理了异步状态问题,它关注的 URLSession.shared.rx.response(request: URLRequest(url: searchURL)).retry(3) 的状态。
在 map 中我们对结果进行了基本的解析,如果响应状态码为 403 表示请求受到限制,返回 limitExceeded 。当请求正常时,我们对数据进行解析,通过 parseRepositories 和 parseNextURL 方法的到本次请求到的仓库列表和下一页的链接,返回这两个结果。
retryOnBecomesReachable 是这里的错误处理方案。这里我们认为 map 中的一系列 try 方法出现错误也是网络返回错误。
看起来这是一个相对完整的请求处理,我们通过 url 获取到了仓库列表和下一次的 url 。
我们回到 recursivelySearch 方法,在调用 loadSearchURL 方法后,我们可能获得三种情况,未连接到互联网,请求受到限制,正常返回结果。
事实上,对于未连接到互联网这种情况,即 serviceOffline ,在 loadSearchURL 会进行 retry ,所以我们可以不考虑这个情况的错误并直接返回相应的结果。
你可以在运行该工程时进行尝试,当将断开网络连接时,我们无法通过上拉的形式加载更多数据,当我们再次连接网络时,我们会收到此前上拉加载的结果。在这里你无需担心在网络断开时,上拉多次,恢复网络时也请求多次的问题。很快我们就会看到我们是如何处理这个问题的。
当请求受限时,我们会收到 limitExceeded 响应,此时,所有的请求结束,我们会收到一个受限的弹窗,此时再去上拉也不会有请求产生。
到了最有意思的代码部分了,当成功加载本页结果时,我们该如何处理?
成功请求到结果,我们会得到本次请求的仓库列表 newPageRepositories 和下一页的链接 maybeNextURL 。
var loadedRepositories = loadedSoFar
loadedRepositories.append(contentsOf: newPageRepositories)
let appenedRepositories = RepositoriesState(repositories: loadedRepositories, serviceState: .online, limitExceeded: false)
// if next page can't be loaded, just return what was loaded, and stop
guard let nextURL = maybeNextURL else {
return Observable.just(appenedRepositories)
}
return Observable.concat([
// return loaded immediately
Observable.just(appenedRepositories),
// wait until next page can be loaded
Observable.never().takeUntil(loadNextPageTrigger),
// load next page
self.recursivelySearch(loadedRepositories, loadNextURL: nextURL, loadNextPageTrigger: loadNextPageTrigger)
])
还记得 recursivelySearch 的参数 loadedSoFar ,这是之前加载的仓库列表,将两个结果加到一起即可得到当前加载所有仓库列表 loadedRepositories 。
当 maybeNextURL 为 nil 时,表明没有下一页的结果,我们可以直接返回当前所有结果,即 Observable.just(appenedRepositories)。
那么 loadNextPageTrigger 用在哪了?
当存在下一页时,我们就需要 loadNextPageTrigger 了,这里使用的方式有一点小 trick 。
Observable.concat([
// return loaded immediately
Observable.just(appenedRepositories),
// wait until next page can be loaded
Observable.never().takeUntil(loadNextPageTrigger),
// load next page
self.recursivelySearch(loadedRepositories, loadNextURL: nextURL, loadNextPageTrigger: loadNextPageTrigger)
])
使用 concat 连接每次的结果,你可以看到我们 concat 的三个 Observable 第一个是当前请求的结果,我们将立即传递该结果。
我们知道 concat 所有的 Observable 都是当前一个 Observable 结束后,才开始订阅下一个 Observable ,第二个 Observable 通过组合 never 和 takeUntil 达到当 loadNextPageTrigger 有值发射时结束。
当 loadNextPageTrigger 有值发射时,才开始订阅第三个 Observable 即进行下一轮的请求。
对于第三个 Observable 则是 recursivelySearch 的递归调用,我们传递当前获取的所有数据,以及本次请求后的下一页连接,进行新一轮的请求。
回到本文最开始的问题,如何连续请求一个分页列表,直到请求到结尾。
你可以直接删除 GitHubSearchRepositories 中 Observable.never().takeUntil(loadNextPageTrigger), 一行代码,再次运行就是预期的效果。
至于为什么这能正常的工作,可能就要留给读者思考了。需要回顾的一点是,我们是通过递归的方式完成了多页加载方案,以及我们没有添加任何一个单独的变量维护请求到的列表数据。